ChatGPTを筆頭に生成AIサービスは世界的に広がってきており、ビジネスで活用されることも増えてきました。
多くのメリットをもたらしている一方で、回答の正確性に問題点があることもわかってきています。
そんな中、その弱点を補う手段として注目されているのが、RAG(検索拡張生成)です。
本記事では、そんなRAGの仕組みや活用法を解説します。
RAG(検索拡張生成)とは?
RAGとは「Retrieval Augmented Generation」の略で、日本語では「検索拡張生成」と訳されます。
生成AIの一種であるLLMのテキスト生成に、信頼性の高い外部データベースの検索を組み合わせることで、出力の精度を高める技術です。
※LLMは自然言語処理に特化した生成AIの一種で、学習した膨大なデータを元にテキスト生成や文章要約を行う技術のこと。
「検索機能」と「生成AI」の弱点を補う技術
「検索機能」は「質問者が検索した用語に合う内容」を羅列することしかできないため、その中から知りたい情報を探し出すには時間がかかります。
「生成AI」は学習済みの情報についてしか回答できないという弱点があります。
例えばChatGPTの場合、インターネット上に公開されている情報を学習しているため、それ以外の情報に関する質問に対して虚偽の回答をする場合があります。
そんな「検索機能」と「生成AI」の弱点を補う技術として今注目を集めているのがRAGです。
RAGは外部のデータベースから情報を探して回答を生成する仕組みです。
質問内容を加味して回答を提示してくれるので、検索結果から知りたい情報を探す手間が省けます。
また、あらかじめ学習させるデータベースをコントロールすることで、意図しない回答を防ぐことができるのです。
RAGの仕組み
RAGは大きく分けて検索、生成の2つのフェーズで動作します。
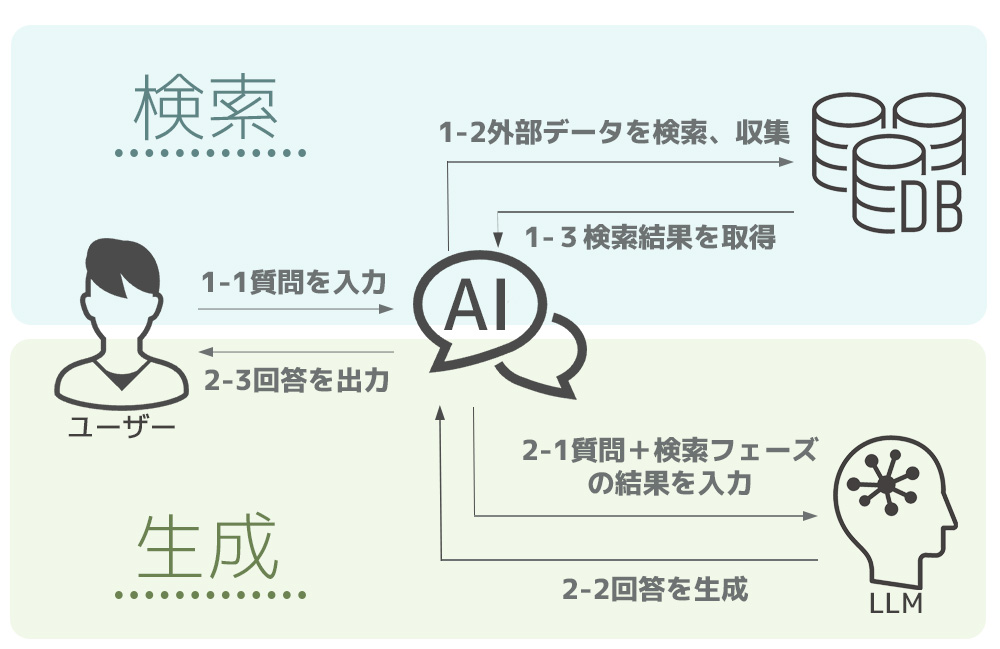
1.検索フェーズ
1)ユーザーがAIチャットなどに質問を入力
2)AIチャットが外部データベースを検索し、適したデータを収集
3)検索結果を取得
2.生成フェーズ
1)ユーザーの質問と検索フェーズで取得した結果を使い、AIチャットがLLMにプロンプトを入力する
2)LLMが回答を生成し、AIチャットに返答
3)チャットAIがLLMから得た回答をユーザーに出力
ファインチューニングとの違い
RAG以外に生成AIの性能を向上させる方法にファインチューニングがあります。
RAGとファインチューニングの違いは生成AIに学習させるかどうかです。
ファインチューニングは生成AIモデルに新たな情報を追加学習させ、AIが扱える情報を増やすことができます。
一方RAGは生成AIに学習させるのではなく、生成AIが情報を参照できるように外部データベースを用意する仕組みです。
RAGはデータベースを更新するだけで、新たな情報が反映できるところが利点です。
RAGを使うメリット
生成AIの精度を高めることができるRAGは、LLM単体で運用するときと比べてメリットが多々あります。
回答の正確性
LLMのみで回答を生成すると、情報が古かったり、ハルシネーションを起こすリスクがあります。ハルシネーションとは、もっともらしい誤情報(事実には異なる内容や文脈とは無関係な内容)を生成することです。
RAGを使うことで回答元となる情報を管理できるので、信頼できる情報のみをデータベースに登録すれば、誤った回答をすることがありません。
また、回答の根拠となる情報源が明確なため、ファクトチェックも容易になります。
情報更新が容易
LLMの知識をアップデートするには、ファインチューニングと呼ばれる追加学習が必要となります。
RAGはあらかじめ登録した正確な外部情報を検索させるため、ファインチューニングの必要がありません。
ファインチューニングにかかる手間とコストを削減することができ、効率的に最新の情報を反映することができます。また、分野に応じた専門性が高い情報を組み込むことも可能です。
社内独自の情報にも活用できる
生成AIは主にインターネット上にある公開情報を元に回答を生成しているため、「非公開の情報」を取り扱えないという特徴があります。
一方RAGは、企業独自の非公開情報など自社独自のデータをセットすることができるので、より活用の幅が広がります。
例えば、社内規定や顧客情報を設定して、社内のナレッジベースや顧客分析などに利用できます。
企業のニーズに合わせた回答ができるため、業務効率化や生産性向上に役立てられるでしょう。
RAGを使う際の注意点
さまざまなメリットがあるRAGですが、利用には注意点もあります。
回答に時間がかかる
RAGは外部データベースや情報元の検索を行う分、生成AIに比べて回答に時間がかかる傾向にあります。
データベースの情報量が多かったり、同時リクエストが生じる場合は特に注意が必要です。
対策として検索データの絞り込み、インデックスの活用、ハードウェアの増強などの方法があります。
回答の精度が参照元データによって左右される
RAGに登録したデータベースの情報が不正確であったり、古い情報の場合、出力される回答結果は不正確なものになってしまいます。
情報のファクトチェックや定期的なメンテナンスを行い、常に新しい情報を参照できるようにしましょう。
実装が難しい
RAGは「生成」と「検索」を組み合わせる高度なシステムであり、構築するためには高い技術力と専門知識が求められます。
具体的には、適切なデータベースの選定や情報整理、検索アルゴリズムの実装、生成AIとの連携といった専門的なスキルが必要になってきます。
そのため、RAGを実装する場合は専門スキルを持つ人材を確保したり、外部のRAGソリューションを導入するなど、自社にとって最適な方法を模索しながら進めていくことも重要です。
RAGの活用方法

マーケティングの効率化
マーケティングの分野では、市場調査や競合分析など幅広く活用できるでしょう。
顧客データや市場調査、アンケートなどを登録すると、そのデータを使った分析を行うことができます。
RAGを使うことで大量のデータを効率的に分析でき、データ間の関連性や傾向を見つけることを容易にしてくれます。
最新のトレンドや情報を反映した、精度の高いアプローチが可能になります。
カスタマーサポート
担当オペレーターがFAQデータベースから検索した情報を元に回答することで、正確で一貫性のある問い合わせ対応が可能になります。
また、問い合わせ対応を自動化することで、人が対応する工数を抑制し、人件費の削減にもつながります。
営業資料などのコンテンツ作成
ChatGPTなどの生成AIサービスでもコンテンツを作成できますが、自社独自の形式や文体に沿ってコンテンツを生成させるには追加学習が必要になります。
RAGを使えば、参考となる社内独自の資料を元に、資料作成やメール文を作成することができます。
まとめ
RAGは今までの検索機能、生成AIの弱点を補える技術として注目を集めています。
導入することで生成AIの実用性を大きく向上させることができるので、今後ますます重要な技術となっていくでしょう。
ソーウェルバーではSNSの投稿をAIを使って分析し、ユーザーの潜在的ニーズや関心を抽出・分析できるツール「HAKURAKU」を提供しています。
まずは御社の状況や目的をお伺いしながら最適なご提案ができればと思いますので、ご興味がある方はぜひお気軽にお問い合わせください。